2. Background
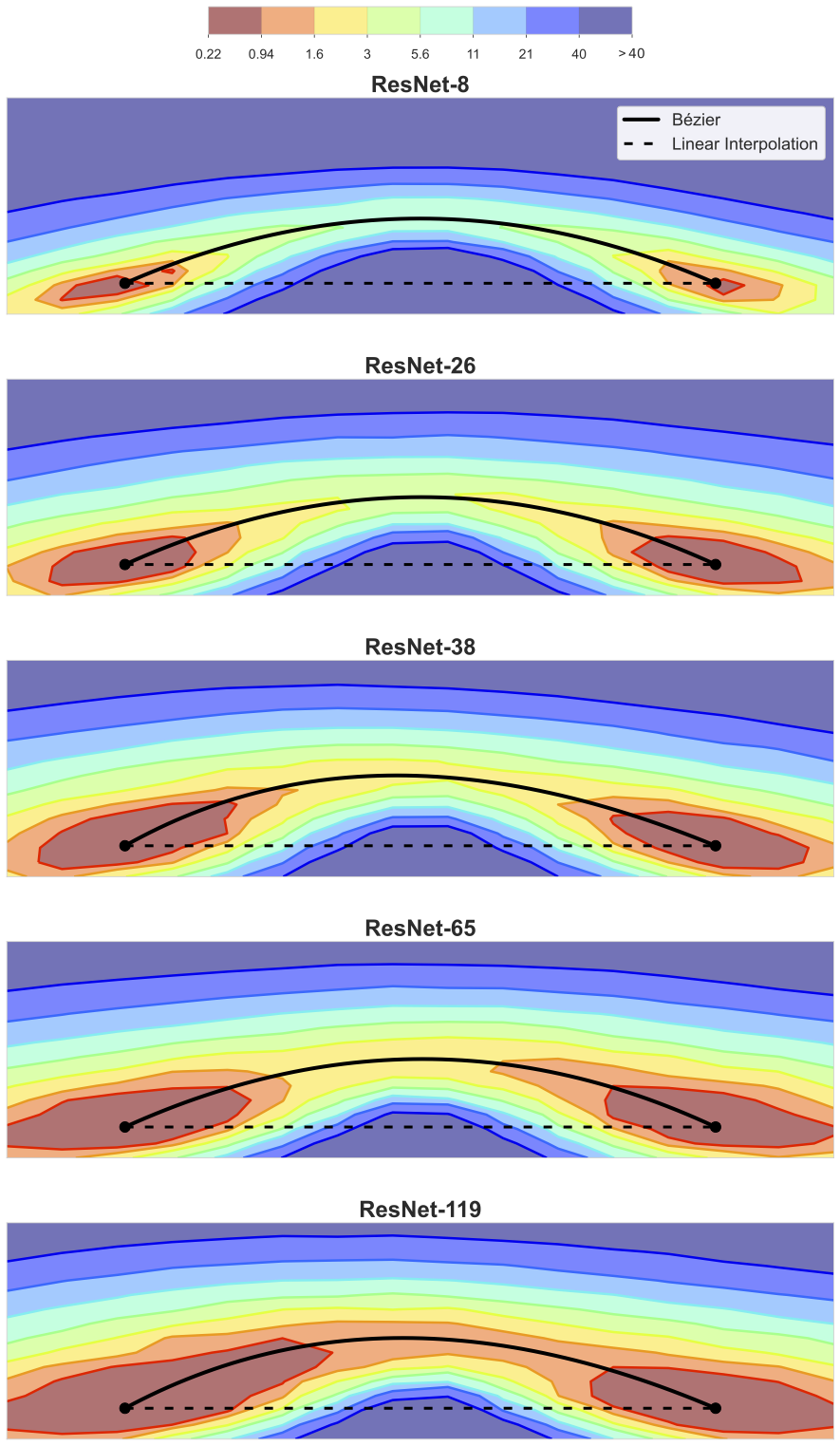
Empirical and theoretical studies have demonstrated that wider networks tend to exhibit mode connectivity: where distinct minima are connected by a smooth, low-loss path
[1, 2]. These networks tend to occupy regions of the loss landscape that are smoother, with shorter and less pronounced barriers between minima. This characteristic suggests that wider models, by virtue of their increased parameterization, might allow for greater flexibility in optimization, potentially leading to more robust solutions.
However, most prior work has focused on the existence of connectivity, rather than the
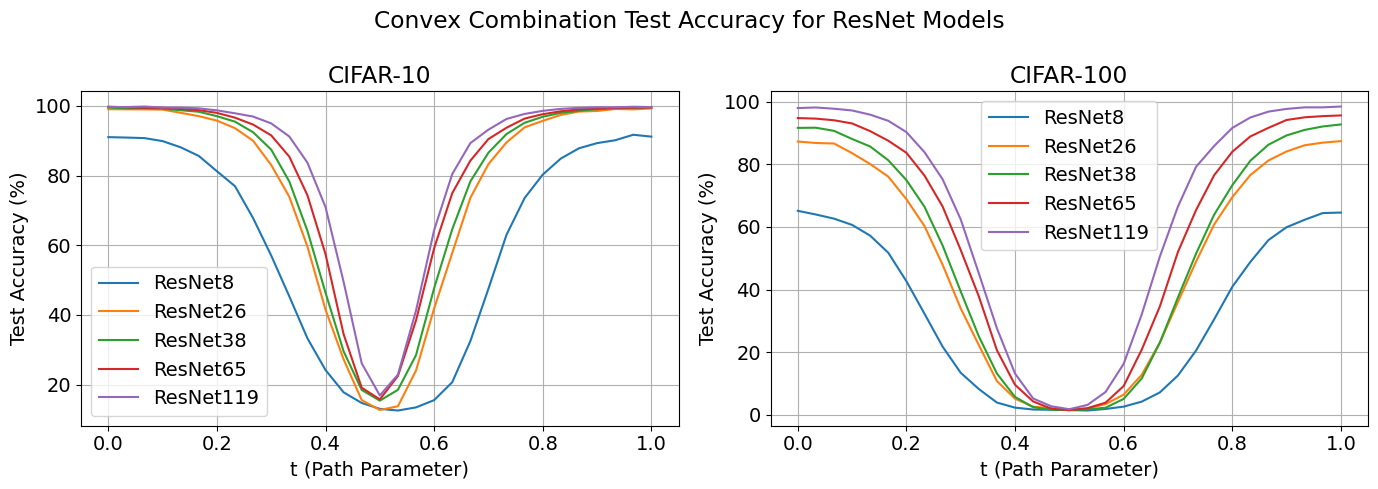
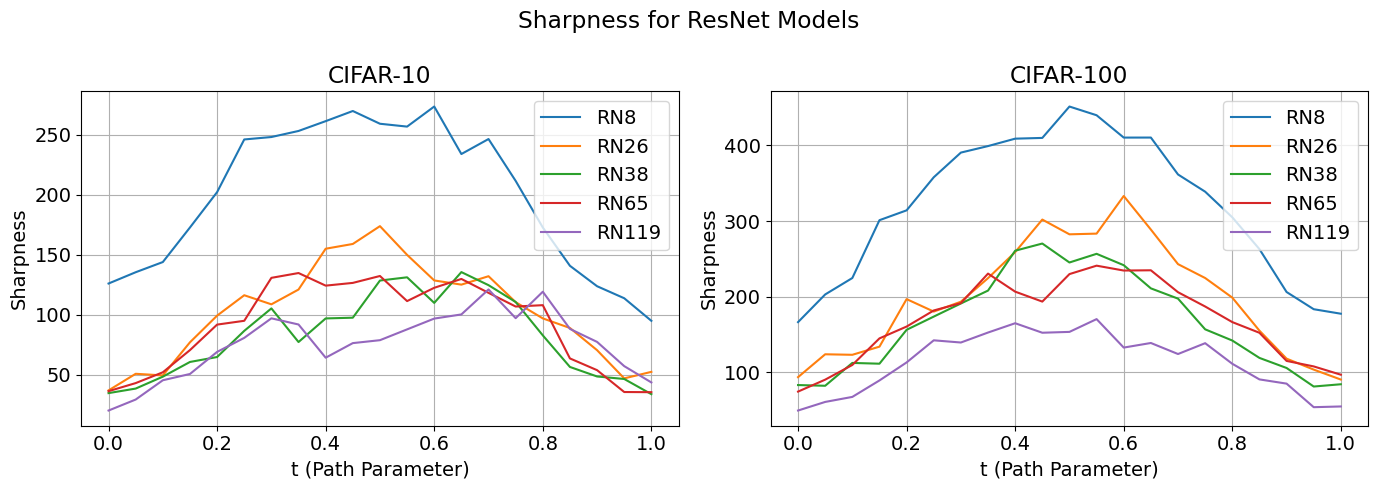
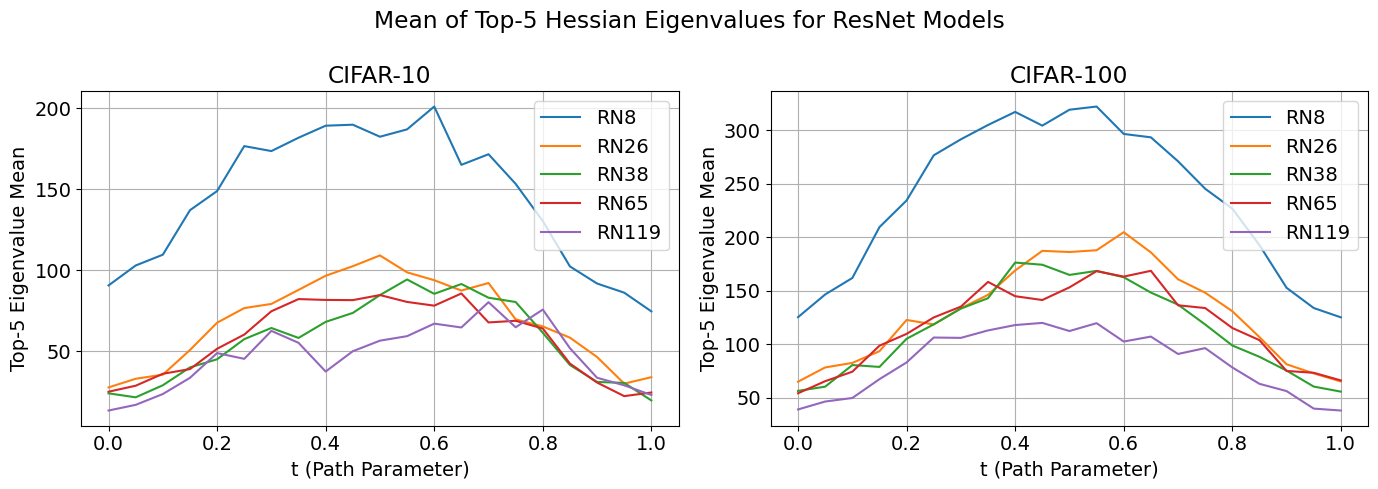
geometry of these connections. In particular, even fewer studies have measured how landscape properties, such as barrier height and path sharpness, vary not just within one path, but across varying architectural factors like depth in practical deep learning settings on real datasets (e.g., ResNet or CNNs on CIFAR-10).
Moreover, while increased connectivity through overparameterization has been linked to improved generalization, this relationship is not without limits
[3, 4]. Beyond a certain degree of overparameterization, increased capacity may no longer improve generalization. Larger models might exhibit wider but shallower basins in the loss landscape, potentially impairing test performance on out-of-distribution data. Furthermore, increasing depth and width might give opposing results
[5]. The precise conditions under which the benefits of increased connectivity plateau, and how the loss landscape geometry contributes to this effect, remains underexplored.
The collective body of existing research confirms the central role of overparameterization in shaping the loss landscape
[6, 7]. It has been established that the set of optimal solutions in networks where the number of parameters significantly exceeds the number of data points is not discrete but rather forms a high-dimensional submanifold
[8, 9]. Awareness of this phenomenon fundamentally changes the optimization challenge. Finding a good solution requires finding not only low-loss minimum, but also a minimum that generalizes well, a property not reflected in the loss itself. This has motivated work to study the effect of hyperparameters such as learning rate and batch size on the width of the minima that stochastic gradient descent (SGD) converges to
[10]. Furthermore, dedicated flatness-aware optimization strategies, such as sharpness-aware minimization (SAM)
[11] and stochastic weight averaging (SWA)
[12], have been developed to actively seek out flat minima
[13].
Furthermore, a substantial area of research has focused on the relationship between optimization and flat minima, hypothesizing that the flatness of a basin correlates directly with a model's superior generalization ability
[14]. However, the connection between these macroscopic landscape properties, like the existence of flat minima, and the microscopic geometry of the connections between them, like path curvature and sharpness, remains loosely quantified, particularly in the context of controlled architectural variations like depth on modern architectures
[6, 7].
Thus, a significant gap remains in rigorously and empirically linking the degree of overparameterization to the quantitative geometry of the optimization landscape. This motivates a systematic investigation of how overparameterization shapes the geometry of the loss landscape, and how this, in turn, influences key properties like generalization. By studying these aspects in a controlled and thorough manner, we aim to uncover insights that could inform the design of more efficient architectures and optimization strategies, ultimately leading to more reliable and interpretable models.
Overparameterized networks tend to form connected, flatter regions of the loss landscape,
which has been linked to better optimization and generalization.
Flatness-aware optimization strategies like sharpness-aware minimization (SAM)
and stochastic weight averaging (SWA) have been developed to actively seek out flat minima.
How these flat, connected regions change with model size remains poorly understood.
Bridging this gap requires studying the geometry of paths between solutions across architectures.